There is no computer even remotely as powerful and complex as the human brain. The lumps of tissue ensconced in our skulls can process information at quantities and speeds that computing technology can barely touch.
Key to the brain’s success is the neuron’s efficiency in serving as both a processor and memory device, in contrast to the physically separated units in most modern computing devices.
There have been many attempts to make computing more brain-like, but a new effort takes it all a step further – by integrating real, actual, human brain tissue with electronics.
It’s called Brainoware, and it works. A team led by engineer Feng Guo of Indiana University Bloomington fed it tasks like speech recognition and nonlinear equation prediction.
It was slightly less accurate than a pure hardware computer running on artificial intelligence, but the research demonstrates an important first step in a new kind of computer architecture.

However, while Guo and his colleagues followed the ethics guidelines in the development of Brainoware, several researchers from Johns Hopkins University note in a related Nature Electronics commentary the importance of keeping ethical considerations in mind while expanding this technology further.
Lena Smirnova, Brian Caffo, and Erik C. Johnson, who weren’t involved with the study, caution, “As the sophistication of these organoid systems increases, it is critical for the community to examine the myriad of neuroethical issues that surround biocomputing systems incorporating human neural tissue.”

The human brain is kind of jaw-droppingly amazing. It contains an estimated 86 billion neurons, on average, and up to a quadrillion synapses. Each neuron is connected to up to 10,000 other neurons, constantly firing and communicating with each other.
To date, our best effort to simulate the activity of the brain in an artificial system barely scratched the surface.
In 2013, Riken’s K Computer – then one of the most powerful supercomputers in the world – made an attempt to mimic the brain. With 82,944 processors and a petabyte of main memory, it took 40 minutes to simulate one second of the activity of 1.73 billion neurons connected by 10.4 trillion synapses – around just one to two percent of the brain.
In recent years, scientists and engineers have been trying to approach the capabilities of the brain by designing hardware and algorithms that mimic its structure and the way it works. Known as neuromorphic computing, it is improving but it’s energy-intensive, and training artificial neural networks is time-consuming.
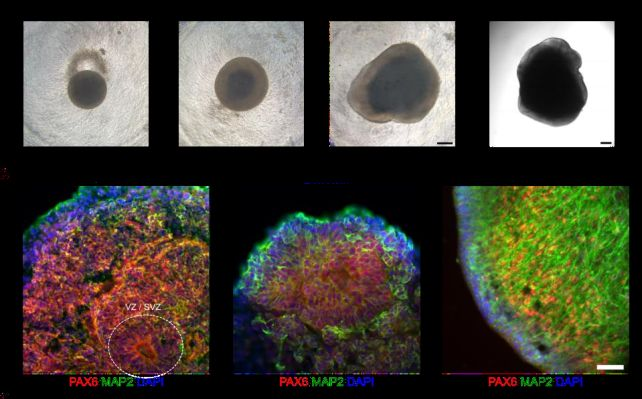
Guo and his colleagues sought a different approach using real human brain tissue grown in a lab. Human pluripotent stem cells were coaxed into developing into different types of brain cells that organized into three-dimensional mini-brains called organoids, complete with connections and structures …….
full article … https://www.sciencealert.com/scientists-built-a-functional-computer-with-human-brain-tissue