Low power requirements for photons (instead of electrons) may make deep learning more practical in future self-driving cars and mobile consumer devices
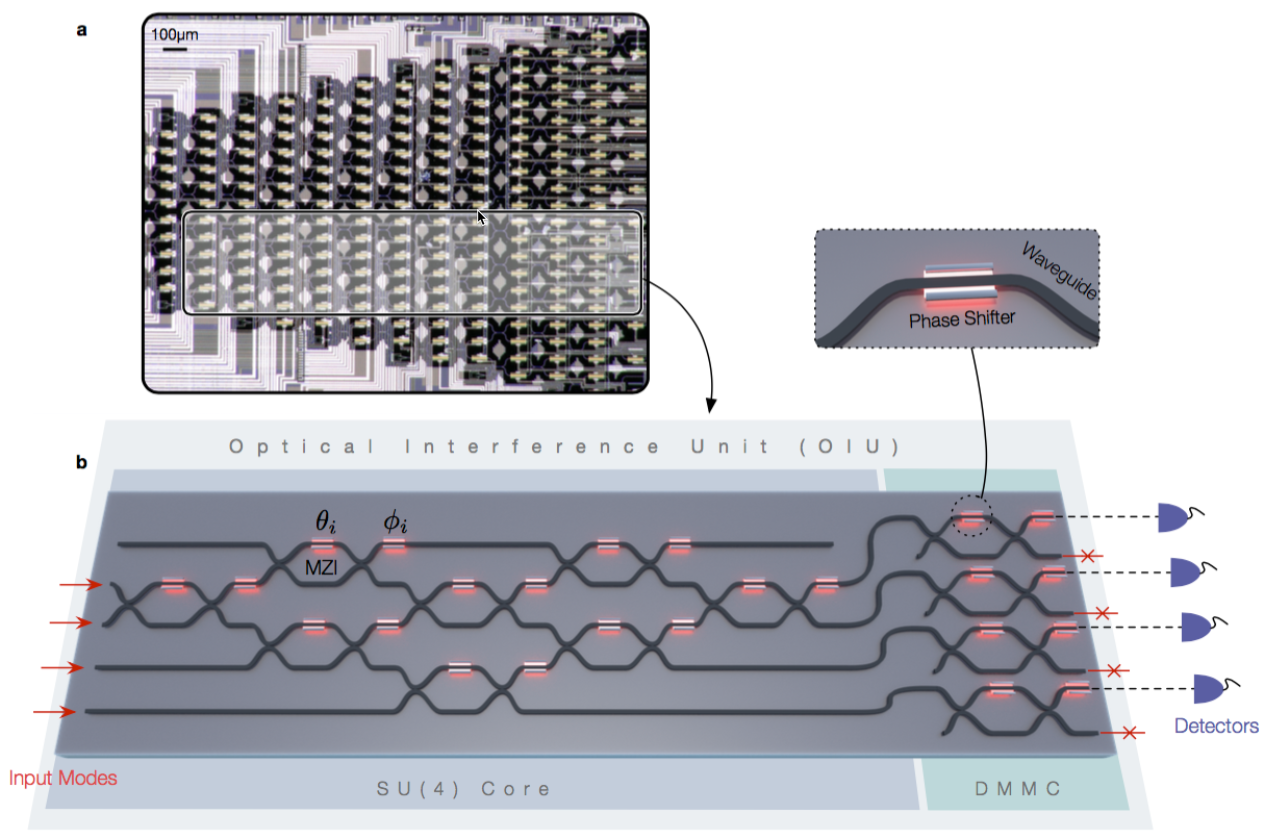
(a) Optical micrograph of an experimentally fabricated on-chip optical interference unit; the physical region where the optical neural network program exists is highlighted in gray. A programmable nanophotonic processor uses a field-programmable gate array (similar to an FPGA integrated circuit ) — an array of interconnected waveguides, allowing the light beams to be modified as needed for a specific deep-learning matrix computation. (b) Schematic illustration of the optical neural network program, which performs matrix multiplication and amplification fully optically. (credit: Yichen Shen et al./Nature Photonics)
A team of researchers at MIT and elsewhere has developed a new approach to deep learning systems — using light instead of electricity, which they say could vastly improve the speed and efficiency of certain deep-learning computations.
Deep-learning systems are based on artificial neural networks that mimic the way the brain learns from an accumulation of examples. They can enable technologies such as face- and voice-recognition software, or scour vast amounts of medical data to find patterns that could be useful diagnostically, for example.
But the computations these systems carry out are highly complex and demanding, even for supercomputers. Traditional computer architectures are not very efficient for calculations needed for neural-network tasks that involve repeated multiplications of matrices (arrays of numbers). These can be computationally intensive for conventional CPUs or even GPUs.
Programmable nanophotonic processor
Instead, the new approach uses an optical device that the researchers call a “programmable nanophotonic processor.” Multiple light beams are directed in such a way that their waves interact with each other, producing interference patterns that “compute” the intended operation.
The optical chips using this architecture could, in principle, carry out dense matrix multiplications (the most power-hungry and time-consuming part in AI algorithms) for learning tasks much faster, compared to conventional electronic chips. The researchers expect a computational speed enhancement of at least two orders of magnitude over the state-of-the-art and three orders of magnitude in power efficiency.
“This chip, once you tune it, can carry out matrix multiplication with, in principle, zero energy, almost instantly,” says Marin Soljacic, one of the MIT researchers on the team.
To demonstrate the concept, the team set the programmable nanophotonic processor to implement a neural network that recognizes four basic vowel sounds. Even with the prototype system, they were able to achieve a 77 percent accuracy level, compared to about 90 percent for conventional systems. There are “no substantial obstacles” to scaling up the system for greater accuracy, according to Soljacic.
The team says is will still take a lot more time and effort to make this system useful. However, once the system is scaled up and fully functioning, the low-power system should find many uses, especially for situations where power is limited, such as in self-driving cars, drones, and mobile consumer devices. Other uses include signal processing for data transmission and computer centers.
The research was published Monday (June 12, 2017) in a paper in the journal Nature Photonics (open-access version available on arXiv).
The team also included researchers at Elenion Technologies of New York and the Université de Sherbrooke in Quebec. The work was supported by the U.S. Army Research Office through the Institute for Soldier Nanotechnologies, the National Science Foundation, and the Air Force Office of Scientific Research.
Abstract of Deep learning with coherent nanophotonic circuits
Artificial neural networks are computational network models inspired by signal processing in the brain. These models have dramatically improved performance for many machine-learning tasks, including speech and image recognition. However, today’s computing hardware is inefficient at implementing neural networks, in large part because much of it was designed for von Neumann computing schemes. Significant effort has been made towards developing electronic architectures tuned to implement artificial neural networks that exhibit improved computational speed and accuracy. Here, we propose a new architecture for a fully optical neural network that, in principle, could offer an enhancement in computational speed and power efficiency over state-of-the-art electronics for conventional inference tasks. We experimentally demonstrate the essential part of the concept using a programmable nanophotonic processor featuring a cascaded array of 56 programmable Mach–Zehnder interferometers in a silicon photonic integrated circuit and show its utility for vowel recognition.
References from:
http://www.kurzweilai.net/learning-with-light-new-system-allows-optical-deep-learning
Yichen Shen et al. Deep learning with coherent nanophotonic circuits. Nature Photonics (2017) doi:10.1038/nphoton.2017.93



